
Nisus Writer recently added a feature that allows you to extract editable text from your photos, scans, PDFs, and other images. This process is often called optical character recognition (aka OCR).
Let’s see how text extraction works using a COVID relief notice I recently received from the United States government:

Once the image is in Nisus Writer Pro document, select it and use the Extract Text From Image command to generate an editable text version of the image:

Most of the text is correct and in sequence. There are a few minor errors and text misplacements, like the number 6 appearing before the title– perhaps caused by the Treasury Department’s seal alongside the main textual content.
Let’s try a few others images, like this paperback book and store receipt:
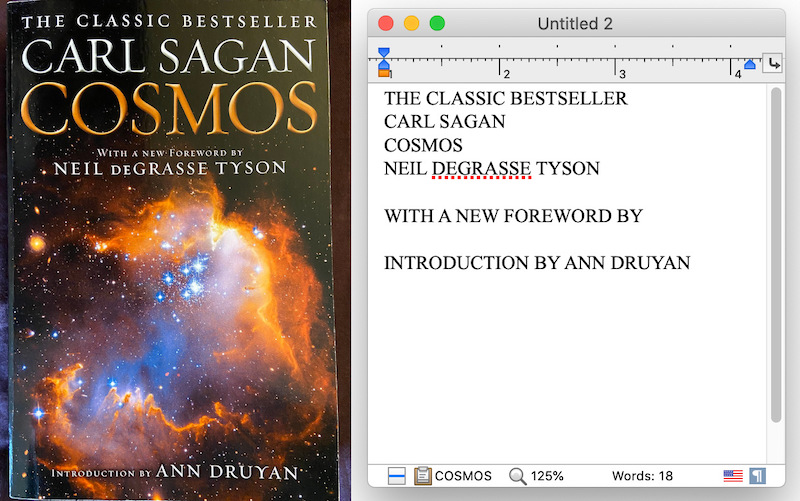

Overall pretty good! Usually editing extracted text is a better starting point than retyping something entirely.
The accuracy of the extraction will depend on a variety of factors including the quality of the image, whether text is slanted or rotated, the language and words in the text, and your system version. Nisus Writer uses Apple’s machine learning capabilities to accomplish this task, and requires at least macOS 10.15 Catalina.
Hopefully you’ll find a good use for this new feature.
Thanks for this new and useful feature.
Terrific feature! Thanks, Martin!
(Curious that Apple provides this OCR engine to developers but hasn’t implemented it in Preview or Pages.)
Tip for PDFs: I discovered that some PDFs have embedded data that confuses the OCR. I solved the problem by using Preview or Acrobat to export the PDF to TIFF (with lossless LZW compression), and then pasting the TIFF into a Nisus document.
Thanks for the tip @Bob! It’s unexpected that PDF metadata confuses or changes OCR output, but it’s certainly possible. The full image data (including any encoded metadata) is given to macOS during text detection.
I’m not sure why Apple doesn’t include these OCR features in Preview or Pages when they’re available to all macOS apps. I will however say that it’s not exactly a quick plug-and-play situation. Nisus Writer does a fair amount of bookkeeping and post-processing to combine the detected text before it can be inserted into your document.
Awesome!
Is this feature – OCR – functioning correctly in any language? f.x. danish.
@Poul: I expect OCR to work for a variety of languages, but I don’t know specifically which ones Apple used to train their machine learning. This may actually depend on your macOS system version.
You may improve the OCR results for Danish by first applying the proper language to the image in your Nisus Writer document, eg: use the menu Format > Language. Nisus Writer will pass the relevant language information onward to macOS during the OCR scan.
Pingback: LittleBITS: TidBITS Formatting Bug, Ransomware Protections, More OCR in Images - TidBITS